Dzisiaj chciałbym przedstawić pewien powszechny problem z Azure Load Balancerem. Przyjmijmy następujący scenariusz:
- Klient posiada aplikację on-premises z load balancerem,
- Ta aplikacja składa się z kilku modułów,
- Każdy węzeł puli hostuje zestaw modułów,
- Niektóre moduły korzystają z usług świadczonych przez inne moduły,
- Moduły działają niezależnie,i używają Load Balancera jako proxy do pozostałych modułów wchodzących w skład aplikacji,
- Używany jest nie tylko HTTP, ale też conajmniej jeden inny protokół oparty na TCP,
- Klient chce przenieść infrastrukturę do Chmury Azure.
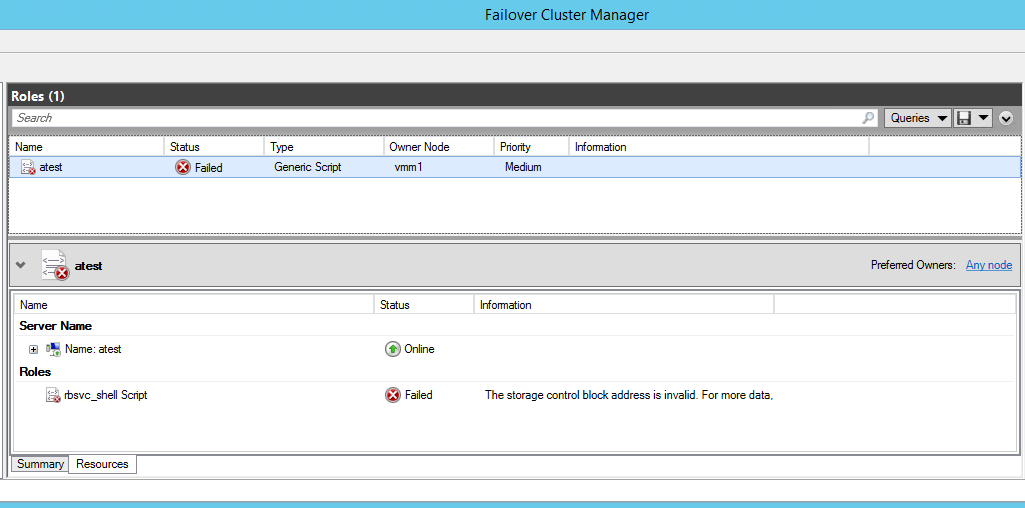
Przykład takiego scenariusza jest opisany w następującym artykule KB CyberArk: Artykuł KB CyberArk.
Microsoft opisuje ten przypadek w przewodniku po rozwiązywaniu problemów z Azure.
Możemy tam przeczytać, że:
Jeśli wirtualna sieć jest skonfigurowana z wewnętrznym load balancerem, i jeden z uczestniczących w niej węzłów backendowych próbuje uzyskać dostęp do wewnętrznego frontu load balancera, to mogą wystąpić problemy z komunikacją, gdy ruch jest mapowany z powrotem do źródłowej VM. Taki scenariusz nie jest obsługiwany.
I oczywiście, to prawda. Sprawdźmy przyczynę tego problemu.
Jak wspomniałem wcześniej, nasz klient chce przeprowadzić migrację „shift and lift” dla swojej infrastruktury CyberArk. Innymi słowy, chce użyć jak najwięcej wbudowanych usług w Chmurze. W takiej sytuacji Azure Load Balancer jest naturalnym wyborem.
Poniżej przytoczyłem przykład projektu architektonicznego CyberArk:

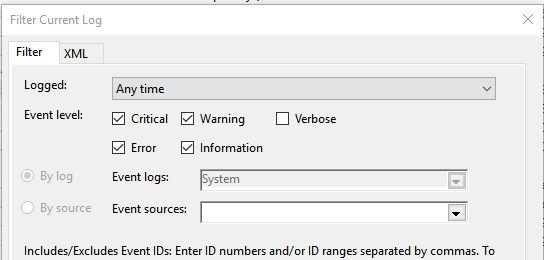
Żeby lepiej wyjaśnić przycznę problemu, najpierw przedstawię niektóre właściwości i ograniczenia Azure Load Balancera:
- Azure Load Balancer działa tylko na warstwie 4 modelu OSI/ISO,
- Azure Load Balancer działa przy użyciu standardowych metod zrównoważenia obciążenia pracy – czyli źródłowe i docelowe adresy IP oraz porty TCP,
- Azure Internal Load Balancer używa wirtualnego adresu IP (VIP) z sieci klienta, co pozwala na zachowanie ruchu wewnątrz vNet,
- Azure VM może być częścią tylko jednego wewnętrznego i jednego zewnętrznego Load Balancera,
- Tylko podstawowy interfejs sieciowy (vNIC) danej Azure VM może być częścią backend pool Load Balancera. Tylko ten interfejs może mieć skonfigurowaną domyślną bramę,
- Azure Load Balanver nie wykonuje translacji adresów IP wychodzących (SNAT). On po prostu nie ma przypisanego adresu IP wychodzącego, tylko przychodzący. Oznacza to, że Azure Load Balancer zmienia tylko adres docelowy z własnego VIP na podstawowy adres IP VMki podczas przetwarzania reguł NAT lub zrównoważania obciążenia. Z perspektywy maszyny wirtualnej w Azure, Azure Load Balancer jest całkowicie przeźroczysty i niewidoczny.
To ostatnie ograniczenie jest przyczyną naszego problemu. Microsoft stwierdza (powtórzmy to, to jest kluczowe!):
mogą wystąpić problemy z komunikacją, gdy ruch jest mapowany z powrotem do źródłowej VM
Dzieje się tak dlatego, że po opuszczeniu Azure Load Balancera pakiet IP będzie miał taki sam adres źródłowy i jak adres docelowy. Zgodnie z RFC 791, sekcja 3.2 taka sytuacja nie powinna się zdarzyć i platforma Azure odrzuca te pakiety IP jako spoofing.
Mając to na uwadze, możemy teraz spróbować znaleźć jakieś rozwiązanie. Z punktu widzenia architektury, musimy stworzyć takie warunki, gdzie adres źródłowy będzie różnił się od adresu docelowego po przejściu przez load balancer. Znaczy to tyle, że nasza maszyna wirtualna musi mieć dodatkowy adres IP.
Dodatkowe adresy IP na karcie sieciowej Azure vNic są obsługiwane w Azure, ale tylko podstawowy adres IP z danego interfejsu może być domyślnie używany jako źródło pakietu IP. Oznacza to, że nie możemy wykorzystać tej funkcji w naszym scenariuszu.
Inną możliwością jest dodanie kolejnej karty sieciowej (vNic) do VM. To również jest wspierane. Maszyna wirtualna w Azure może mieć jedną podstawową kartę sieciową i do ośmiu dodatkowych kart sieciowych. Dodatkowe karty sieciowe mogą być przypisane do dowolnej podsieci w ramach vNet podstawowej karty sieciowej. Więc maszyna wirtualna w Azure nie może należeć do więcej niż jednego vNet Azure. To nam wystarczy. Musimy utworzyć dodatkową podsieć i dołączyć do niej drugą kartę sieciową.
Dodatkowe karty sieciowe mają jeszcze jedno ograniczenie. Nie mogą mieć domyślnej trasy. W zasadzie nie mogą mieć żadnej trasy. Dodatkowe karty sieciowe mogą gromadzić ruch, ale trudno jest przez nie coś wysłać. Więc takie naiwne podejście nie będzie działać. Adres źródłowy nadal zostanie ustawiony na podstawowy adres IP karty sieciowej.
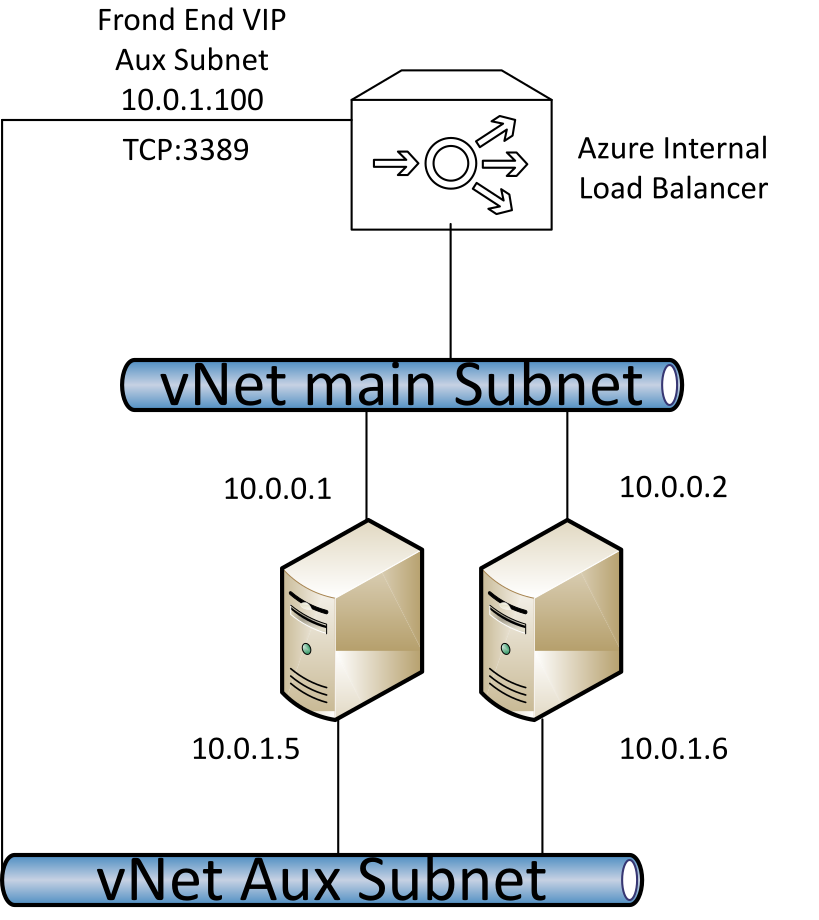
Sztuczka polega na zmianie VIP Internal Load Balancera.
To jedyny sposób na wymuszenie przesłania pakietu IP przez drugą kartę sieciową. Gdy VIP wewnętrznego Load Balancera jest z tej samej podsieci co dodatkowa karta sieciowa, możemy wykorzystać domyślne zachowanie IP – adresy IP z lokalnej sieci są osiągane poprzez lokalny segment ethernetu lub inne medium. Normalnie, to jest kwestia optymalizacji, ale w tym scenariuszu jest to nasza jedyna szansa.
Ostateczną architekturę przedstawiłem na poniższym obrazku:
Happy Load Balancing!